At least for the finite difference method, you may normalize the gradient as a unit vector before the weight update, i.e.
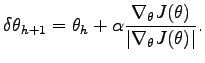
This usually improves the learning speed. For a more exact description of the methods and the equations see the lecture slides.
All the policy gradient methods should be compared with respect to the learned speed. Therefore, create a performance curve (x-axis : number of episodes seen by the algorithm, y-axis: summed reward of current parameter value) for each algorithm. In order to get a reliable estimate, use the average over at least 10 trials for each curve.