Download the Reinforcement Learning (RL) MATLAB Toolbox and the example files4. Adapt the mountain car demo example and apply RL to the following learning task.
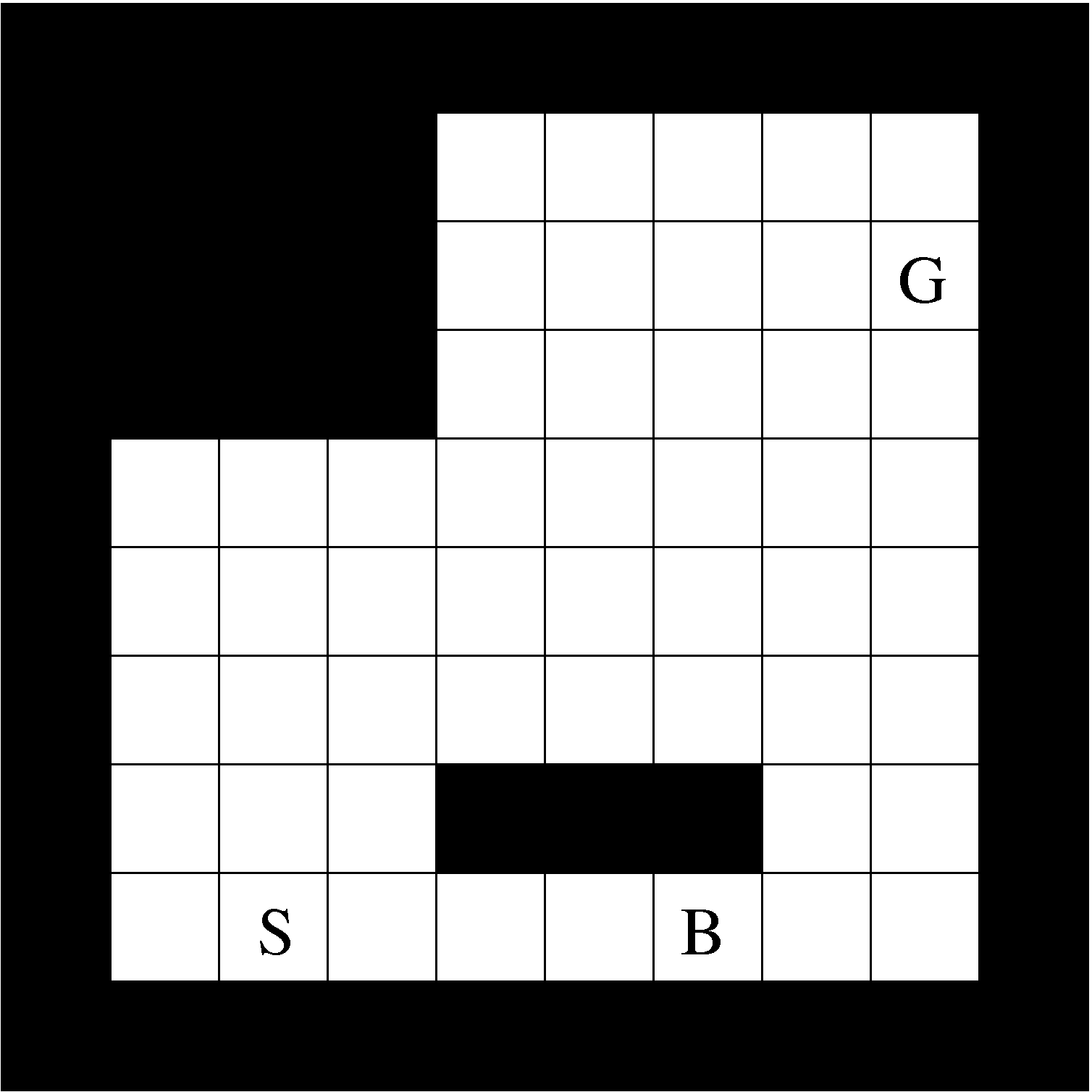
Consider the gridworld shown in Figure 4. Implement this environment with the RL Toolbox as an undiscounted (
![]() ), episodic task with a start state at
), episodic task with a start state at ![]() and a goal state at
and a goal state at ![]() .
The actions move the agent up, down, left and right, unless he bumps into a wall, in which case the position is not changed. The reward is
.
The actions move the agent up, down, left and right, unless he bumps into a wall, in which case the position is not changed. The reward is ![]() on all normal transitions,
on all normal transitions, ![]() for bumping into a wall, and 0
at the bonus state marked with
for bumping into a wall, and 0
at the bonus state marked with ![]() .
.
Use Q-Learning and SARSA without eligibility traces to learn policies for this task. Use ![]() -greedy action selection with a constant
-greedy action selection with a constant
![]() . Measure and plot the online performance of both learning algorithms (i.e. average reward per episode), and also sketch the policies that the algorithms find. Explain any differences in the performance of the algorithms. Are the learned policies optimal? Submit your MATLAB code.
. Measure and plot the online performance of both learning algorithms (i.e. average reward per episode), and also sketch the policies that the algorithms find. Explain any differences in the performance of the algorithms. Are the learned policies optimal? Submit your MATLAB code.